
K均值聚类的定义及相关基础知识大家自行百度查询,这里不做赘述;本文主要从实操角度介绍K均值聚类的SPSS操作方法及一直困扰大家的K值选择问题。
本文中的案例数据,如有需要的可以评论留言获取,支持邮箱或百度网盘!
一、SPSS K均值聚类的基本步骤
1、数据读取,并检查数据质量(图一)
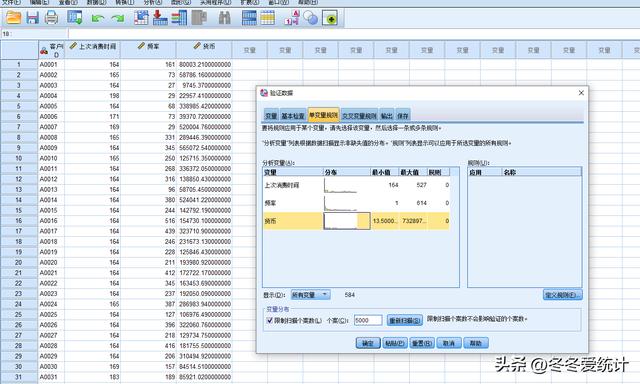

图一
图二
通过描述统计可以看出数据波动较大,且维度间的量纲差距也较大,因此在K均值分析前需要将数据进行标准化,去除量纲影响。
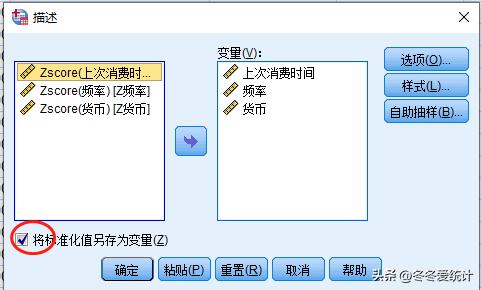
图三
在分析——描述性统计中对话框中勾选将标准化值另存为变量即可完成数据的标准化。
二、K均值分析
选择分析-分类-K均值分类

图四
变量选择标准化后的数据,个案选择客户ID,初始聚类数选择K=5,最大清代次数选择99
图五
同时保存聚类成员与中心距离
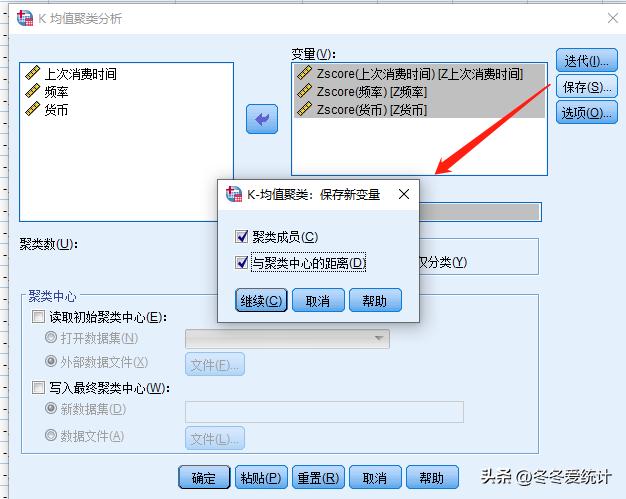
图六
勾选选项中的相关菜单
图七
三、结果解读
1、初始聚类中心与经过迭代计算后的聚类中心,一共经过18次迭代实现收敛
图八
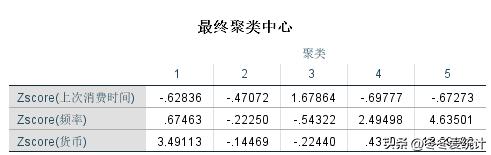
图九

图10
2、ANOVA 表记录了假设检验的结果,结果显著表明聚类有效
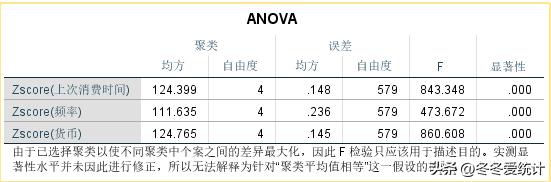
图11
3、根据积累结果绘制三维散点图,根据实际业务场景进行应用
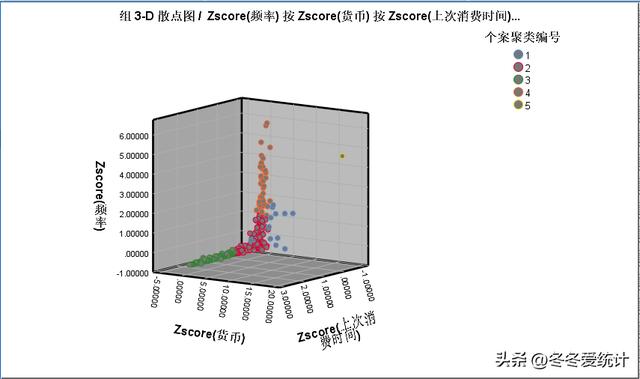
图12
上面的步骤简要介绍了K均值聚类的方法步骤,但是大家肯定好奇为什么选择初始K值为5,而不选的别的数字,下面就介绍一下关于K值选择的方法。
1、根据业务场景明确需要的聚类数目,一般RMF聚类选择则3;
2、根据不同K值的误差均方和变化,选择合适的K值(肘线法)
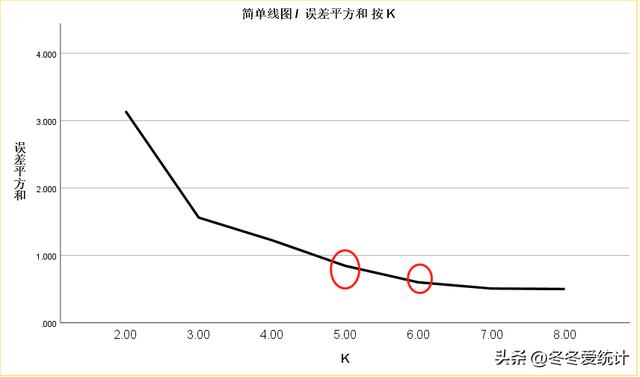
图13
选择考K=5,或者K=6时,达到误差下降的拐点。
创业项目群,学习操作 18个小项目,添加 微信:790838556 备注:小项目!
如若转载,请注明出处:https://www.zoodoho.com/26109.html
相关推荐
-
如何推广软件新功能,如何推广软件的英语作文
如果我们有一款app软件,我们应该要先学会app推广吗?app推广需要注意什么,怎么推广更有效果呢?接下来我们详细地介绍一下app推广的一些方法。 市场推广现在分两种:一种付费推广…
-
18岁身份证号码和真实姓名最新2022,18岁身份证号码和真实姓名大全
俗话说得好,爱美之心人皆有之,很多人为了让自己更加完美,会通过整容的方式完善自己提高颜值,甚至搞营销,做噱头,总而言之导致现代审美愈发畸形化,人们对美的看法越来越病态。 不得不说,…
-
涨价去库存谁提出来的,涨价去库存的逻辑
最近,房地产政策是一波接着一波,从金融16条开始,降低存款准备金,贷款展期等一系列政策出台以后,昨天夜里有来一波重磅炸弹,容许房地产企业进入资本市场融资发债了,看看这个政策的密集程…
-
微信58个表情含义图,微信58个表情含义图_图解
笑容透露心理 心理学家们现在发现:笑是人类与他人交流的最古老的方式之一,而在此之前,笑只被看作是人类幽默感的体现。人类笑是为了和别人团结一致或者嘲笑他们,要么用笑和别人调情。 笑容…
-
营业执照在快手商家认证能认证几个快手号,快手有营业执照可以认证么
“抖音企业号是企业商家在抖音做生意的一站式经营平台,做生意第一步就是要开通企业号"。 抖音建立的的商家准入门槛便是企业号认证,便是我们俗称的抖音蓝V。只有经过抖音官方对营业…
-
家纺商家必看的5个批发平台!
跟着互联网关盈余渐渐闪现,线上2C电商情况趋势增速加重,富厚了用户人群的物资生活,同时中国2B电商领域情况趋势分泌率晋升,行业迎来庞大盈余。 家纺行业也出现了很多的企业级电商…
-
唯品会的鞋子都是正品吗知乎,唯品会的鞋子都是正品吗知乎推荐
不知道从什么时候开始,这届年轻人非常喜欢攒黄金。一位叫小王的年轻人,毕业2年选择在小县城工作,每个月几千元的工资并不高,但吃住都在家里,一个月还能剩2000来元,但她没有选择存银行…
-
闲鱼系列课程|不要再找了,你想知道的所有货源渠道都在这里
导读做闲鱼最头疼的一点,我相信就是货源了,每天都有人问:“谁有好的货源分享一下”、“你这个渠道价格不便宜啊”,之类的声音,捕手其实也是没有太好的解决办法,我有一定的货源,但有些是不…
-
锦纶面料属于什么档次冲锋衣,锦纶是什么面料优缺点冲锋衣_面料
不想看原理的朋友,请直接跳转最后面看结论。 一、鸭绒与鹅绒差别大不大? 同等蓬松度的鸭绒、鹅绒是一样的,羽绒的蓬松度是羽绒的体积,蓬松度一样羽绒体积是一样的,而且鸭绒与鹅绒是同样的…
-
吕布最后怎么了,终究是吕布
接上文书:李肃信誓旦旦的说要去丁原那劝吕布来降董卓。成功了没有?且听我接着道来:话说吕布告诉李肃,说我在丁原这里也是出于无奈,哪里甘心久居人下呢?李肃一听吕布上套了,便接着说:良禽…
-
三年期定期存款利率2022,五年期定期存款利率2022
2022年11月,国内各类银行人民币存款全新利息表 各类银行人民币存款利率表 银行 活期存款 定期存款(整存整取) 三个月 半年 一年 二年 三年 东亚银行 0.300 1.375…
-
基督徒男女交往禁忌送给我的花能拿回家吗,基督徒一般送什么花
做情感咨询这些年,我见过形形色色的爱情故事: 有的人想要考验伴侣的真心,最终弄巧成拙;有的人在关系里步步退让,最终仍是不被珍惜;有的人在分手后彻夜难眠,最终也挽回不了爱。 R…